序言
摘要: 最近一直在写一个脚本语言,主要对标对象是润乾的集算器。感觉润乾的集算器有一定的应用场景,但是类似excel的方式严重影响编程可接受程度,另外其有些语法感觉与java习惯也非常不一致,因此就自己动手写了一个,目前正在紧张的验证中,验证完毕将完全开源。 欢迎感兴趣的同学mark,到时一起玩耍。 最终开源的git地址是:http://git.oschina.net/tinyframework/tinyscript 正常是完善好文档再开源,如果fork超过1000+,马上开源,开源协议是Apache V2。
运行
我们提供了Eclipse和Idea插件,可以直接右键运行扩展名为tinyscript的文件哦:
示例
99表
for(i=1;i<=9;i++){ for(j=1;j<=i;j++){ System.out.printf("%d*%d=%d\t",i,j,i*j); } System.out.println(); }
运行结果
1*1=1 2*1=2 2*2=4 3*1=3 3*2=6 3*3=9 4*1=4 4*2=8 4*3=12 4*4=16 5*1=5 5*2=10 5*3=15 5*4=20 5*5=25 6*1=6 6*2=12 6*3=18 6*4=24 6*5=30 6*6=36 7*1=7 7*2=14 7*3=21 7*4=28 7*5=35 7*6=42 7*7=49 8*1=8 8*2=16 8*3=24 8*4=32 8*5=40 8*6=48 8*7=56 8*8=64 9*1=9 9*2=18 9*3=27 9*4=36 9*5=45 9*6=54 9*7=63 9*8=72 9*9=81
数组
abc={1,2,4,9,6,3}; println(max(abc)); println(min(abc)); println(avg(abc)); println(median(abc)); println(varp(abc)); println(stdevp(abc)); def={"aa","bb","cc"}; println(max(def));
运行结果
9 1 4.166666666666667 3.5 7.138888888888889 2.6718699236468995 cc
列表
a=[1,2,3,4,5]; b=[2,3,4,6]; println(a-b); println(a+b); println(a&b); println(a^b); c=["abc","def","gg"]; d=["abc","def1","gg1"]; println(c+d); println(c-d); println(d-c);
运行结果
[1, 5] [1, 2, 3, 4, 5, 6] [2, 3, 4] [1, 5, 6] [abc, def, gg, def1, gg1] [def, gg] [def1, gg1]
当然也可以有更好玩的动作
a=[1,2,3]; println(a); a++; println(a); a*=3; println(a); b=["abc","def","ghijk"]; println(b.length());
[1, 2, 3] [2, 3, 4] [6, 9, 12] [3, 3, 5]
当然,来点lambda也是可以的:
add(a,b)->{ return a+b;}; System.out.println(add(2,4));
运行结果:
6
Java语法可以直接使用:
import java.util.*; list=[1,2,3,9,8,7]; Collections.sort(list); println(list);
运行结果:
[1, 2, 3, 7, 8, 9]
当然脚本语言中的结果也可以在Java里面完美使用,完全没有违和感。
java的所有属性和方法都可以直接被调用:
a=[1,2,3,4,5]; println(a.getClass().getName()); b=[]; for(i:a){b.add(i*i)}; println(b);
运行结果:
java.util.ArrayList [1, 4, 9, 16, 25]
这里也再次证明它和java都是完全一致的,从这个意义上说,他可以是ava的扩展。
当然,做它不是为了玩玩,当然是期望有比较简单的处理,这里的“#”表示集合元素的一个具体元素
a=[1,2,3,4,5]; println(a.filter(#%2==1)); println(a.filter(#%2==0)); println(a.filter(#>3&&#%2==0));
运行结果:
[1, 3, 5] [2, 4] [4]
上面的意思就是,对这个列表进行过滤,分别是取奇数、偶数和大于3的偶数。
由于后面的表达式可以任意编写,这样就有了非常好的适用场景了:
class User{ age,name; } userList=[]; for(i=1;i<9;i++){ user=new User(); user.name="user"+i; user.age=i; userList.add(user); } filterList=userList.filter(#.age>3&&#.age%2==1); println(filterList);
运行结果:
[User[name=user5,age=5], User[name=user7,age=7]]
上面的逻辑是,取出年龄大于3且年龄是单数的用户列表。
Map
map={"abc":1,"aaa":2,"ddd":4}; map1={"abc":1,"aaa":2,"bbb":3}; println(map); println(map.get("abc")); println(map+map1); println(map^map1); println(map&map1); println(map1-map);
运行结果:
{aaa=2, abc=1, ddd=4} 1 {aaa=2, abc=1, bbb=3, ddd=4} {bbb=3, ddd=4} {aaa=2, abc=1} {bbb=3}
全排列
ele=[1,2,3]; for(i:ele){ ele.permute(i,(e) -> { println(e); }); println("=============="); }
运行结果
[1] [2] [3] ============== [1, 1] [1, 2] [1, 3] [2, 1] [2, 2] [2, 3] [3, 1] [3, 2] [3, 3] ============== [1, 1, 1] [1, 1, 2] [1, 1, 3] [1, 2, 1] [1, 2, 2] [1, 2, 3] [1, 3, 1] [1, 3, 2] [1, 3, 3] [2, 1, 1] [2, 1, 2] [2, 1, 3] [2, 2, 1] [2, 2, 2] [2, 2, 3] [2, 3, 1] [2, 3, 2] [2, 3, 3] [3, 1, 1] [3, 1, 2] [3, 1, 3] [3, 2, 1] [3, 2, 2] [3, 2, 3] [3, 3, 1] [3, 3, 2] [3, 3, 3] ==============
当然你也可以对各种排列进行相关的处理
水仙花数
class Narcissus{ compute(num){ for(i=100;i<num;i++){ a=i/100; b=(i-a*100)/10; c=i-a*100-b*10; if(pow(a,3)+pow(b,3)+pow(c,3)==i){ System.out.println(i); } } } } narcissus=new Narcissus(); narcissus.compute(999);
运行结果:
153 370 371 407
可以看到普通的算法是上面这个样子的。
采用全排列的算法是如下的:
elements = [0,1,2,3,4,5,6,7,8,9]; elements.permute(3,(e) -> { value=e[1]*100+e[2]*10+e[3]; if(pow(e[1],3)+pow(e[2],3)+pow(e[3],3)==value){ System.out.println(value); } });
运行结果:
0 1 153 370 371 407
可以看到比普通的算法多了两个0,1,原因是这里没有对000和001进行处理,直接转为0和1了,如果000=0、001=1,那么0、1也可以算作是符合条件的。
石头剪刀布游戏
info=["石头","剪刀","布"]; for(i=0;i<10;i++){ mine=randInt()%3; your=randInt()%3; if(mine==your){ printf("平了,都是%s\n",info[mine+1]); }else{ if(mine==your-1||mine==2&&your==0){ printf("我赢了,我是%s你是%s\n",info[mine+1],info[your+1]); }else{ printf("我输了,我是%s你是%s\n",info[mine+1],info[your+1]); } } }
运行结果:
我输了,我是布你是剪刀 我输了,我是剪刀你是石头 平了,都是石头 我赢了,我是剪刀你是布 平了,都是剪刀 我输了,我是布你是剪刀 平了,都是布 平了,都是石头 我输了,我是布你是剪刀 我赢了,我是石头你是剪刀
看起来玩起普通的算法也是没有任何问题的。
类支持
class User { name,age; User(name,age){ this.name = name; this.age =age; } User(name){ this.name = name; } } user = new User("红薯",18); user2 = new User("tom"); user3 = new User(); //无参构造函数 println(user); println(user2); println(user3);
运行结果:
User[name=红薯,age=18] User[name=tom,age=null] User[name=null,age=null]
计算连续3天涨停的股票
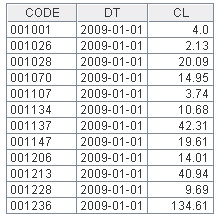
下面是某证券交易所一个月内的日收盘价记录,其中CODE列为股票代码,DT为日期,CL为收盘价。试找出这个月内曾连续三天涨停的股票。为避免四舍五入产生的误差,涨停的比率定为9.5%。
部分数据请见下图(完整记录请见附件stockRecords.txt,之后示例也遵守此规范)
class Example1 { /* 统计一个月内连续三天涨停的股票 */ countStock(path) { ratio = 0.095d; ds = readTxt(path); groupds =ds.insertColumn(3,"UP").convert(CL,"double").group(CODE).sortGroup("DT ASC"); groupds.subGroup(1,1).update(UP,0d); //每月的第一天涨停率为0 groupds.update(UP,(CL[0]-CL[-1])/CL[-1]); //之后的每天统计当天的涨停率。 resultds = groupds.filterGroup(UP[0]>ratio && UP[1]>ratio && UP[2]>ratio); return resultds; } } m = new Example1(); groupDs= m.countStock(\"src/test/resources/StockRecords.txt\"); for(int i=0;i<groupDs.getRows();i++){ println("code="+groupDs.getData(i+1,1)); }
这次的代码有点复杂,因此这里解释一下:
设定涨停增长率为0.095及以上。
从文本文件读取数据,当然从数据库读取也是一样的,只要改成如下即可:
ds=[[select * from stockRecords]];
然后增加一个列,并把CL列转成double,然后按CODE分组,然后按DT排序。
然后每支股票的第一天的增长率设置为0,然后,计算后面的增长率。
然后过滤连续3天增长率都大于涨停的股票。
运行结果:
code=201745 code=550766 code=600045 code=700071
计算订单邮费
某B2C网站需要计算订单的邮寄费用,大部分情况下,邮费有包裹的总重量决定,但是,当订单的价格超过300美元时,提供免费付运。详细规则如下面的mailCharge表所示:
| FIELD | MINVAL | MAXVAL | CHARGE |
| COST | 300 | 1000000 | 0 |
| WEIGHT | 0 | 1 | 10 |
| WEIGHT | 1 | 5 | 20 |
| WEIGHT | 5 | 10 | 25 |
| WEIGHT | 10 | 1000000 | 40 |
该表记录了各个字段在各种取值范围内时的邮费。例如,第一条记录表示,cost字段取值在300与1000000之间的时候,邮费为0(免费付运);第二条记录表示,weight字段取值在0到1(kg)之间时,邮费为10(美元)。
某B2C网站需要计算订单的邮寄费用,大部分情况下,邮费有包裹的总重量决定,但是,当订单的价格超过300美元时,提供免费付运。详细规则如下面的mailCharge表所示:
| FIELD | MINVAL | MAXVAL | CHARGE |
| COST | 300 | 1000000 | 0 |
| WEIGHT | 0 | 1 | 10 |
| WEIGHT | 1 | 5 | 20 |
| WEIGHT | 5 | 10 | 25 |
| WEIGHT | 10 | 1000000 | 40 |
该表记录了各个字段在各种取值范围内时的邮费。例如,第一条记录表示,cost字段取值在300与1000000之间的时候,邮费为0(免费付运);第二条记录表示,weight字段取值在0到1(kg)之间时,邮费为10(美元)。
下面是该网站的一些订单:
| ID | COST | WEIGHT(KG) |
| JOSH1 | 150 | 6 |
| DRAKE | 100 | 3 |
| MEGAN | 100 | 1 |
| JOSH2 | 200 | 3 |
| JOSH3 | 500 | 1 |
请计算这些订单的详细邮费。
class Example2 { /* 根据规则统计不同订单的邮费 */ countMailCharge(path1,path2){ ruleDs = readTxt(path1).convert(MINVAL,"int").convert(MAXVAL,"int").convert(CHARGE,"int"); orderDs = readTxt(path2).convert(COST,"int").convert(WEIGHT,"int").insertColumn(4,"POSTAGE"); costRuleDs = ruleDs.filter(FIELD=="COST").sort("MINVAL"); //cost维度规则集 weightRuleDs = ruleDs.filter(FIELD=="WEIGHT").sort("MINVAL"); //weight维度规则集 orderDs.match(costRuleDs,COST > MINVAL).update(POSTAGE,CHARGE); //通过match函数匹配COST规则 orderDs.match(weightRuleDs,POSTAGE ==null && WEIGHT > MINVAL && WEIGHT <=MAXVAL).update(POSTAGE,CHARGE); //通过match函数匹配WEIGHT规则 return orderDs; } } m = new Example2(); resultDs=m.countMailCharge(\"src/test/resources/mailCharge.txt\",\"src/test/resources/testOrder.txt\"); for(int i=0;i<resultDs.getRows();i++){ resultDs.absolute(i+1); println("POSTAGE="+resultDs.getData("POSTAGE")); }
运行结果:
POSTAGE=25 POSTAGE=20 POSTAGE=10 POSTAGE=20 POSTAGE=0
统计销售大户
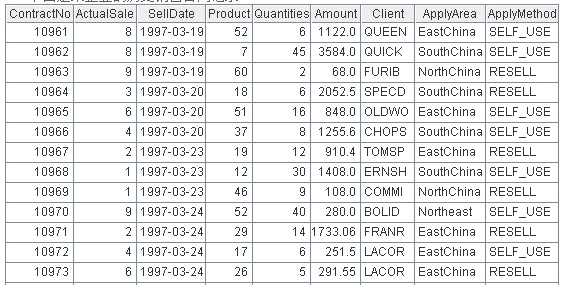
下面是某企业的历史销售合同记录:
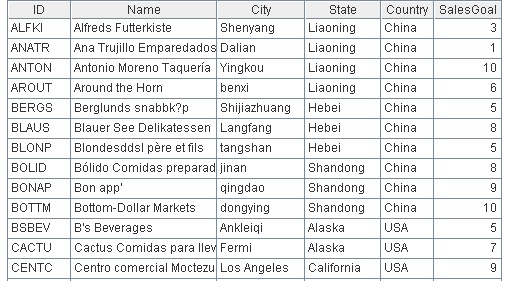
下面是某企业的客户信息表:
某年内按销售额排名的客户,达到一半销售额的前n个客户称为该年的“大客户”,请列出1998年该企业的大客户名单。
class Example3 { /* 统计某年的大客户 */ countVip(){ contractDs = readTxt("src/test/resources/Contract.txt").convert(Amount,"double"); clientDs = readTxt("src/test/resources/Client.txt"); firstDs = contractDs.filter(SellDate.startsWith("1998")).join(clientDs,Client = ID); //过滤1998年的数据,并关联client表 groupDs = firstDs.select("Name","Amount").group(Name); //保留计算字段,并按用户分组 groupDs.sumGroup(Amount); //统计每个用户的金额 halfAmount = groupDs.sort("sumGroup_Amount desc").sum(sumGroup_Amount)/2; list = new java.util.ArrayList(); //建立空序列 groupDs.forEach( (i) -> { halfAmount -= sumGroup_Amount; if(halfAmount>0){ list.add(Name); } } ); return list; } } m = new Example3(); obj=return m.countVip(); for(Object obj:list){ println("name="+obj); }
运行结果:
name=QUICK-Stop name=Save-a-lot Markets name=Ernst Handel name=Mère Paillarde name=Hungry Owl All-Night Grocers name=Rattlesnake Canyon Grocery name=Simons bistro name=Berglunds snabbk?p name=Lehmanns Marktstand name=HILARION-Abastos name=Folk och f? HB
统计客户账户余额
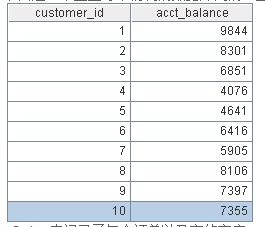
一共涉及四张表,首先是Customers表,记录了客户ID和客户的账户余额:
第二张表是Orders表记录了每个订单以及它的客户:
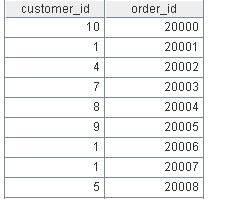
第三张表OrderDetails表记录了每个订单的详细信息,包括订购的产品ID以及数量:
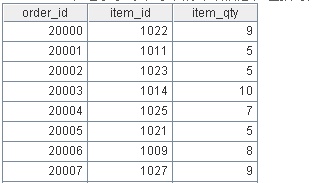
最后一张表Products表记录了企业所有的产品信息:
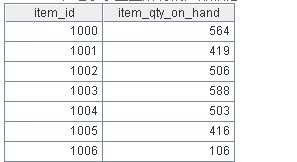
问题是为每一个订购了公司所有产品的顾客求出平均acct_balance(账户余额),并为每一个没有订购所有产品的顾客求出平均账户余额。
class Example4 { /* 统计订购产品的客户账户余额 */ countBalance(){ customerDs = readTxt("src/test/resources/Customers.txt").convert(acct_balance,"double"); orderDs = readTxt("src/test/resources/Orders.txt"); orderDetailDs = readTxt("src/test/resources/OrderDetails.txt"); productDs = readTxt("src/test/resources/Products2.txt"); tempDs = orderDetailDs.join(orderDs,order_id=order_id).join(customerDs ,customer_id=customer_id).copy().select("customer_id","order_id","item_id","acct_balance"); //关联前三张表 groupDs = tempDs.group(customer_id); //按客户分组 groupDs.distinctGroup(item_id); //统计分组客户消费的产品 num = productDs.getRows(); //统计全部产品数目 allProductDs = groupDs.filterGroup(distinctGroup_item_id.size()==num); //购买全部产品的客户分组集 otherDs = groupDs.filterGroup(distinctGroup_item_id.size() < num); //购买部分产品的客户分组集 balance1 = allProductDs.avg(acct_balance); balance2 = otherDs.avg(acct_balance); System.out.println("balance1="+balance1+" balance2="+balance2); } } m = new Example4(); m.countBalance();
运行结果:
balance1=4990.5 balance2=7363.875

